À mesure que de plus en plus d’organisations, d’entreprises et de collectivités passent à l’informatique distribuée en nuage (« cloud computing »), la demande pour des infrastructures de centres de données augmente. Que ceux-ci soient dédiés ou en colocation, ils continuent d’évoluer pour offrir des solutions personnalisées avec des coûts optimisés malgré une complexité croissante et une concurrence planétaire. En ce sens, les titans de la technologie (Google, Amazon Web Services, Microsoft Azure, etc …) investissent dans des installations de très grande taille (« hyperscale ») qui peuvent abriter des milliers et des milliers de serveurs pour répondre à leurs exigences et celles de leurs clients.
L’énergie et la maintenance derrière l’exploitation optimisée des centres de données
À l’échelle mondiale et compte tenu du constat ci-dessus, les centres de données consomment environ 2 % de l’énergie électrique et ce pourcentage pourrait atteindre 8 % selon les projections au vu des tendances actuelles.
Avec un refroidissement responsable jusqu’à 40 % de la consommation d’énergie des centres de données, le design avant-gardiste réunit des serveurs haute densité à la pointe de la technologie et des systèmes de refroidissement hyper performants voire révolutionnaires. Certains opérateurs se tournent vers l’intelligence artificielle (« IA ») ou les énergies renouvelables pour assurer l’alimentation électrique leurs serveurs et celle de l’hébergement dédié. A cette charge importante s’ajoutent toutes celles liées à la maintenance.

Chez RLB, en parfaite connaissance des enjeux et sans à priori, nous préconisons, soutenons et proposons de mettre en œuvre toutes les solutions intelligentes et durables car elles aident nos clients à déterminer voire réduire leur coût global d’exploitation, les coûts liés à la maintenance de l’environnement dédié, leurs consommations d’énergies et leurs émissions de gaz à effet de serre.
Viser l’excellence en matière d’optimisation de la maintenance
En parallèle de la somme de nos expertises en matière d’énergie, nous leur proposons d’atteindre l’excellence dans la maintenance de l’hébergement de leurs datacenters. Laquelle repose sur l’adoption d’une approche proactive, systématique et axée sur la continuité du service visant la haute disponibilité. Pour aider ses clients à y parvenir, RLB développe :
1. Une stratégie de maintenance avancée
Ainsi, l’excellence permet de passer du curatif à l’anticipation avec des politiques de :
- Maintenance préventive rigoureuse en rédigeant un calendrier strict d’inspections, de tests et de remplacements planifiés pour tous les équipements critiques (onduleurs/UPS, générateurs, systèmes et réseaux de refroidissement, batteries, tableaux électriques, protection incendie, etc …). Ceci est crucial pour prévenir les pannes majeures.
- Maintenance prédictive en préconisant d’utiliser des systèmes de GTB-GTC évolués (BMS pour Building Management Systems) associés aux capteurs intelligents de l’internet des objets (IoT) et l’analyse de données (Big Data & IA) pour surveiller en temps réel l’état des équipements. Cela permet de détecter les signaux de défaillance potentielle (vibrations, variations de température, consommation électrique anormale, dépassements de seuil, etc…) avant la panne et de n’intervenir qu’au moment optimal, réduisant l’usure anormale et les coûts d’interventions inutiles.
- Maintenance axée sur la fiabilité en priorisant la sécurisation des systèmes les plus critiques pour la continuité des opérations ou, dit autrement, en concentrant les ressources de maintenance là où un échec aurait l’impact le plus dévastateur sur l’exploitation.
2. Les infrastructures et leur redondance
Où l’excellence est synonyme de résilience par :
- La redondance des systèmes en s’assurant que tous ceux jugés vitaux car critiques (alimentation électrique, refroidissement, protection incendie, réseaux télécom, etc…) sont conçus et réalisés avec une redondance suffisante pour permettre la maintenance d’un composant sans interruption du service.
- Les tests de charge et scénarii de panne : Effectuer régulièrement des tests intégrés en simulant, virtuellement et physiquement, des pannes extrêmes (coupure d’alimentation principale, défaillance d’un groupe froid, rupture de connexion fibre, etc…) pour valider la capacité des systèmes redondants à prendre le relais et l’efficacité des procédures de reprise.
- La gestion permanente de l’hébergement en maintenant des niveaux de température et d’humidité stables et optimaux. La propreté physique du datacenter est également vitale (dépoussiérage régulier des équipements et des planchers surélevés).

3. Processus et Documentation
Les opérations décrites ci-dessus nécessitent des fondations solides s’appuyant sur :
- Des procédures détaillées et standardisées : Documenter méticuleusement toutes les procédures d’exploitation, de maintenance et d’urgence (« back up ») en s’assurant que les équipes d’exploitation les suivent à la lettre et utilisent pleinement un système de Gestion de la Maintenance Assistée par Ordinateur (GMAO) qui répertorie les gammes de maintenance, génère et suit les ordres de travail et archive les comptes-rendus d’intervention.
- La gestion des actifs (Asset Management) en tenant à jour le registre précis de tous les équipements y compris leurs composants sans oublier d’y attacher l’historique de maintenance, les garanties et les inventaires de pièces de rechange (notamment celles concernant les systèmes critiques).
- La pré-planification des opérations d’urgence et de reprise d’activité en mettant en place et en testant régulièrement (au moins annuellement) un plan de reprise après sinistre pour minimiser l’impact d’événements imprévus (incendie, inondation, catastrophe naturelle, rupture des connexions, attaque terroriste, etc…)
4. Compétences et culture
Pour RLB, l’humain reste au cœur de l’excellence opérationnelle par :
- Des recrutements adaptés à des profils de poste très précis complétés de conditions de travail et de rémunération attractives.
- La formation continue et la certification du personnel d’exploitation, tant technique que d’encadrement. Des équipes bien formées identifient plus rapidement et résolvent les problèmes avec plus de précision. De plus, elles capitalisent mieux les retours d’expérience.
- La supervision caractérisée par une surveillance continue en temps réel et une capacité d’intervention rapide 24 heures sur 24, 7 jours sur 7 toute l’année, favorise un cadre où la sécurité – physique et numérique – et la rigueur procédurale sont des priorités absolues.
5. Mesure et amélioration continue
L’excellence se mesure et n’est pérenne que si elle s’améliore en mettant en œuvre :
- Des niveaux de service requis (SLA) et des indicateurs de performance clés (KPI) pour suivre des mesures essentielles comme :
- le taux de disponibilité global (GAR pour global availability rate) en visant le niveau optimum de 99,999% (le fameux « GAR Five Nines »),
- l’efficacité énergétique pour optimiser la consommation,
- le respect des contraintes et normes environnementales,
- l’amélioration continue du temps moyen de réparation (MTTR pour Mean Time To Repair) Ssur chaque système et installation,
- celle du temps moyen entre pannes (MTBF pour Mean Time Between Failures).
- Des audits en réalisant, ou mieux en faisant réaliser par des experts extérieurs, des audits réguliers pour vérifier l’exécution des gammes de maintenance, les procédures de sécurité et la conformité aux normes (ex. : ISO 27001 pour la sécurité, etc…) sans oublier d’identifier les opportunités d’amélioration.
- Et en utilisant le cycle PDCA (Planifier-Développer-Contrôler-Agir), méthodologie bien connue permettant d’affiner sans cesse les processus et les performances.
Comment éviter les erreurs en matières de maintenance ?
Pour éviter les erreurs en matière de maintenance d’hébergement de datacenters, RLB privilégie une stratégie proactive et systématisée face à une approche réactive (réparation après la panne). La grande majorité des pannes sont évitables grâce à la rigueur de l’analyse et à l’anticipation des risques.
1. Erreurs liées à une planification et à une maintenance insuffisantes
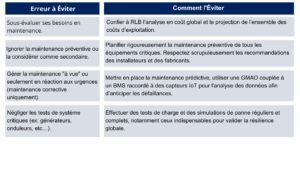
2. Erreurs liées à l’infrastructure et aux capacités électrique et frigorifique
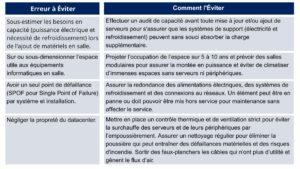
3. Erreurs liées aux procédures et à l’humain
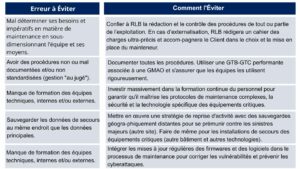
Chercher l’équilibre entre rendement immédiat et valeur à long terme
RLB travaille activement pour de nombreux développeurs de contenu, des hébergeurs à grande échelle et des propriétaires et utilisateurs de datacenters en France, aux Pays-Bas, en Italie, au Danemark, en Suède, en Allemagne, en Irlande et au Royaume-Uni. En sus de l’Europe, le travail des experts de RLB en matière d’estimation et de planification des coûts et d’ingénierie de la valeur aide les propriétaires et utilisateurs de centres de données dans le monde entier.
Depuis l’analyse initiale des besoins jusqu’à l’audit d’exploitation, avec des idées nouvelles et un contrôle de l’exécution sans faille, ils aident à équilibrer les défis immédiats de disponibilité, de sûreté de fonctionnement, de sécurité, d’efficacité énergétique et environnementale et de maitrise du coût global avec une perspective sur le long terme afin que nos clients puissent pérenniser et faire évoluer leurs actifs au fil du temps au meilleur coût.